
Matrix and scalar vector multiplication is not a new concept. It not only predates the 18th century but has been more recently imagined and used in many ALU systems to maximize efficiency and throughput. These basic linear operation spans many application in large scale and small scale computing. This includes FFT calculation, signal processing etc. It is now more important than ever to evaluate the efficiency of the linear algebra operations across multiple machines, programming environments, and library calls, so that we get a better understanding of which ecosystems yields the best efficiency given the operations cost and matrix/vector size.
In this write up we will discuss, test, analyze and compare four basic linear algebra operations (scalar product, matrix-vector product, matrix-matrix product, and integer power of matrix) on multiple machines including AWS Elastic Compute Cloud, ECE compute cluster, and PSC Bridges. We will utilize two different programming languages and environments including both Python (high productivity language) and C (performance oriented language). We will implement them in two variants, by definition, using loops and element-wise array access and via system/math libraries and built-in functions. Each linear operation inputs a random vector (size N) or matrix (size NxN) of increasing input by a factor N*2 until a time limit of 10 minutes is reached or the machine hangs (i.e. memory overflow).
Machine Specifications:
AWS Elastic Compute Cloud
AWS Elastic Compute Cloud is a web service that provides secure, resizable compute capacity in the cloud. For the implementation, we used an instance type A1.large which correlates to 2 cores and and 4GB of storage capacity on a custom built AWS Graviton Processor with 64-bit Arm cores. Amazon EC2 A1 instances deliver significant cost savings and are ideally suited for scale-out and Arm-based workloads that are supported by the extensive Arm ecosystem. Each vCPU on A1 instances is a core of an AWS Graviton Processor. The use cases involve, scaling out workloads such as web servers, caching fleets, and distributed data stores, as well as development environments
PSC Bridges
PSC Bridges is a super computing resource that leverages interactivity, parallel computing, Spark and Hadoop for Big-Data analysis. Bridges comprises over 850 computational nodes. Some including Regular Shared Memory nodes with 128GB RAM each and Large Shared Memory nodes with 3TB RAM each. PSC Bridges' computational nodes supply 1.3018 Pf/s and 274 TiB RAM. The Bridges system also includes more than 6PB of node-local storage and 10PB of shared storage in the Pylon file system. Bridges is a uniquely capable resource for empowering new research communities and bringing together HPC, AI and Big Data.
ECE Computing Cluster
ECE compute cluster is a multicore AFS available to CMUs faculty, staff, and students. ECE compute cluster is used for scalable processes. The primary private site is known as the ECE compute cluster with 32 machines. The ECE computing cluster contains 16 nodes: Intel(R) Pentium(R) D CPU 3.00GHz CPUs, 8 GBytes RAM, 1 Gbit/sec ethernet. Total CPUs (cores): 16 x 2 = 32. The cluster is ideal for small to medium size scaling.
Library’s
Numpy and Intel Math Kernel Library
As background information, we utilize multiple machines in each implementation. We also utilize different library calls including Numpy and Intel MKL. NumPy is a package in Python used for Scientific Computing. Numpy adds support for large, multi-dimensional arrays and matrices, along with a large collection of high-level mathematical function to operate on these arrays. Intel Math Kernel Library (MKL) is a library of optimized math routines for engineering. The Intel Math Kernel Library includes routines and functions optimized for Intel and compatible processor. Aside from these libraries, we utilize simple element wise operations and other built in functions.
SCALABILITY OF LINEAR ALGEBRA
To start, we will breakdown the mathematics involved in each linear algebra operation, discuss the complexity of the algorithmic and programmatic implementation, describe the choice in hardware platform and software infrastructure used, discuss the results, and finally evaluate each performance analysis.
Each result shown is a product in the form of a scalar or matrix. These linear algebra operation can be easily implemented in any programming language. Version 1 of the Python implementation uses built in operations while Version 2 of the Python implementation takes advantage of methods in Numpy. Version 1 of the C programming implementation uses built in operations while Version 2 of the C programming implementation takes advantage of methods in Intel MKL operations. Utilizing large scale resources was needed and necessary because it yields better and more efficient results. As we levy large scale multicore systems, we can expect better results but this does not come without an expense to operation costs. Below are both versions (1 & 2) of the scalar product, matrix-vector product, matrix-matrix, integer of power matrix implementations in both Python and C.
Notes on interpreting graphs: Depicted below are resulting graphs of each linear algebra operation. The title of each graphs highlights, the linear operation being assessed, the chosen machine of operation, and the programming environment. On the x-axis is the size of the vector (n) /matrix (nxn) and on the y-axis is the floating point operation (FLOPS) between each successful operation. The resulting performance analysis shows the FLOPS or operation cost as each matrix or vector size increases. The FLOPS was measured over each increase of n and is given from the below formula:
Flops = (((2*n)^3)/total time running)/1000000000)
Scalar Product
To define multiplication between a vector A and a vector B we need to view the vector as a column vector. We define the scalar-vector product only for the case when the number of column in A equals the number of values in B. So, if A is a size N vector, then the product AB is defined for N column vectors B. If we let AB=C, then C is a scalar. In other words, the values in the vectors determines the scale of the product C. This can be expressed in the form:

Below is Version 1 and Version 2 of the Python and C implementations. Also listed is the resulting operations graph.
# VERSION 1 via built in operations @timeout(500) def dot_product_version1(x, y): #input should be 2 vectors """Dot product as sum of list comprehension doing element-wise multiplication""" return sum(x[i]*y[i] for i in range(len(y))) # VERSION 2 via library calls @timeout(500) def dot_product_version2(x,y): #input should be 2 vectors """Dot product as sum of list comprehension doing element-wise multiplication""" return np.dot(x,y)





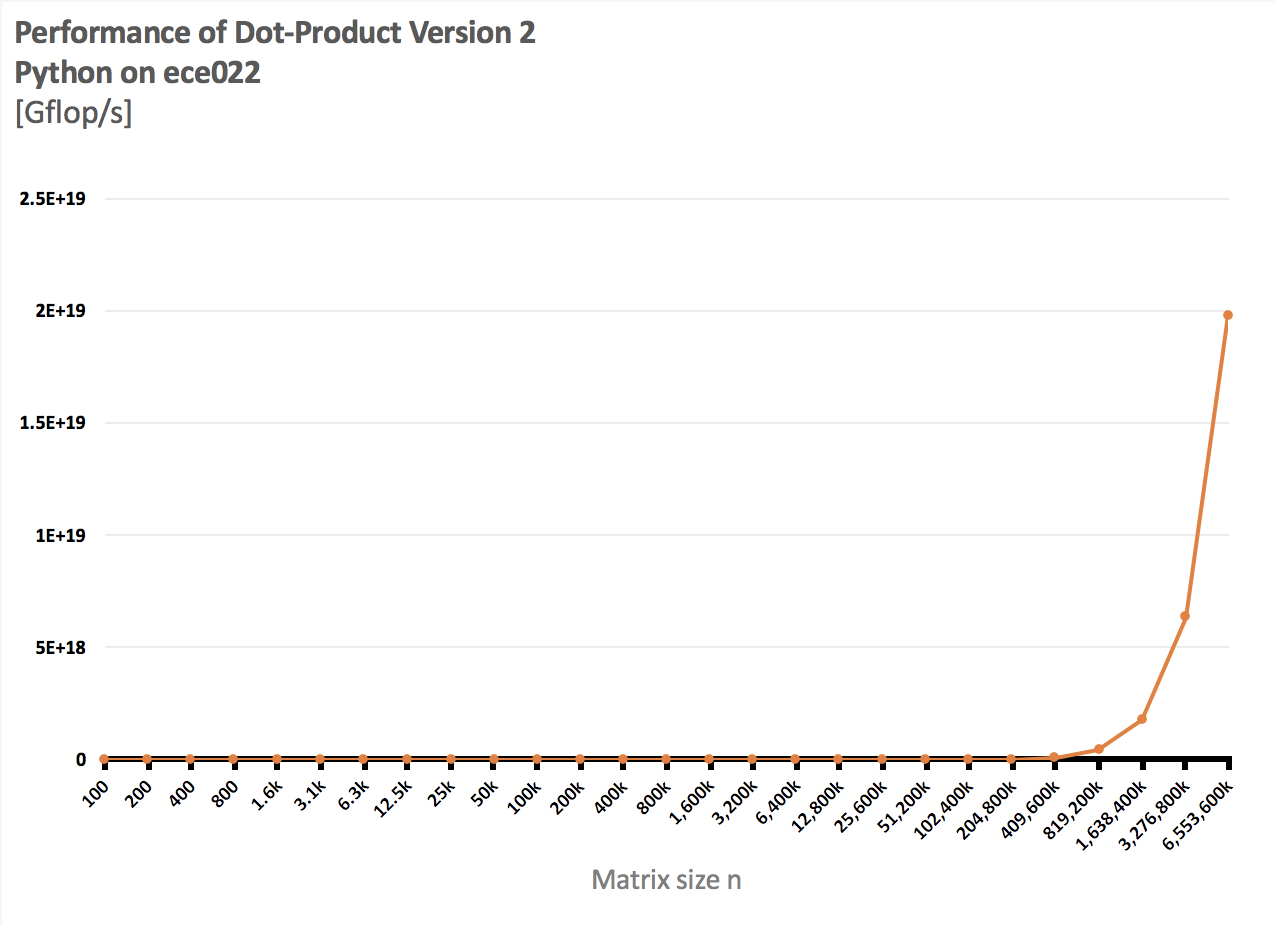
PYTHON DATA ANALYSIS | SCALABILITY AND COMPLEXITY
As we process each graph, we notice that with either version or system, the data follows an increasing exponential trend. As the number of elements in each vector (x-axis) increases, the number of FLOPS also seems to double for larger matrix/vector operation. Looking closer at the graphs, we notice that the ECE computing cloud machine on version 1 of the implementation has the lowest FLOPS. This directly correlates to the linear algebra operation utilizing the least amount of resources to complete the operation. The efficiency rating can be expected given the processing power on ECE computing cloud.
C PROGRAMMING LANGUAGE
# VERSION 1 via built in operation int dot_product(int *c, int *d, size_t n){ """Dot product as sum of list comprehension doing element-wise multiplication""" int sum = 0; size_t i; for (i = 0; i < n; i++) { sum += c[i] * d[i]; } return sum; } # VERSION 2 via library calls int dot_product(int *c, int *d, MKL_INT n)// size_t n){ """Dot product as sum of list comprehension doing element-wise multiplication on MKL""" MKL_INT in cx, incy; float res; incx = 2; incy = 1; res = cblas_sdot(n, (const float *)c, incx, (const float *)d, incy); return res; }






C PROGRAMMING DATA ANALYSIS | SCALABILITY AND COMPLEXITY
As we process each graph, we notice that with either version or system, the data follows an increasing exponential trend excluding version 2 on PSC Bridges. As the number of elements in each vector (x-axis) increase, the number of FLOPS also seems to double for larger matrix/vector operation. Looking closer at the graphs, we notice that the PSC Bridges machine on version 2 of the implementation has the lowest FLOPS. This directly correlates to the linear algebra operation utilizing the least amount of resources to complete the operation. The efficiency rating can be expected given the processing power on PSC and efficiency in storage on the machine.
matrix-vector product
To define multiplication between a matrix A and a vector x we need to view the vector as a column matrix. We define the matrix-vector product only for the case when the number of columns in A equals the number of rows in x. So, if A is an m×n matrix, then the product Ax is defined for n×1 column vectors x. If we let Ax=b, then b is an m×1 column vector. In other words, the number of rows in A determines the number of rows in the product b. This can be expressed in the form:

Below is Version 1 and Version 2 of the Python and C implementations. Also listed is the resulting operations graph.
# VERSION 1 via built in opertions def matrix_vector_multiplication_version1(matrix,vector): """Matrix vector product as sum of list comprehension doing element-wise multiplication""" result = [] for i in range(len(matrix[0])): #this loops through columns of the matrix total = 0 for j in range(len(vector)): #this loops through vector coordinates & rows of matrix total += vector[j] * matrix[i][j] result.append(total) return result # VERSION 2 via library calls def matrix_vector_multiplication_version2(matrix,vector): """Matrix vector product as sum of list comprehension doing element-wise multiplicatio using dot""" return np.dot(matrix,vector)
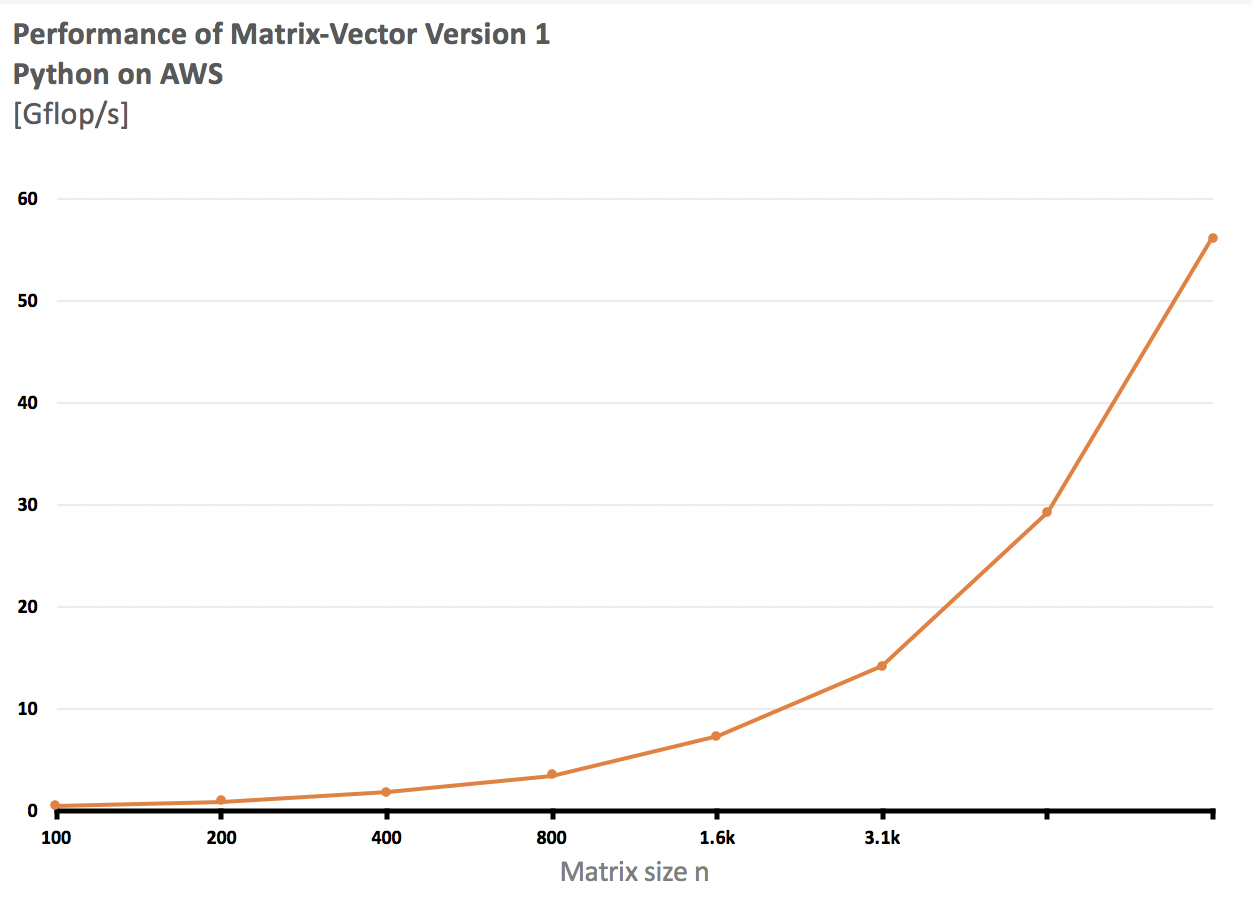





PYTHON DATA ANALYSIS | SCALABILITY AND COMPLEXITY
As we process each graph, we notice that with either version or system, the data follows a slow but increasing trend. As the number of elements in each vector (x-axis) increases, the number of FLOPS also seems to double for larger matrix/vector operations. Version 2 of the matrix-vector operation follows a different path of operation cost. The FLOPS seem to at first increase as the size of the elements increase and then begins to decrease in a monotonic tone. This could be due to the leverage of available cores on the ECE computing cluster. Looking closer at the graphs, we notice that the ECE computing cloud on version 2 implementation has the lowest FLOPS. This directly correlates to the linear algebra operation utilizing the least amount of resources to complete the operation. The efficiency rating is possible because of the limited number of successful operations.
C PROGRAMMING LANGUAGE
# VERSION 1 via built in operations void matrix_vector_mult(size_t m,size_t n, int mat1[m][n], int mat2[n], int res[m][n]) { """Matrix vector product as sum of list comprehension doing element-wise multiplication""" int i, j; for (i=0; i<n; i++){ for (j=0; j<n; j++){ res[j][0] += mat1[j][i] * mat2[i]; }}} # VERSION 2 via library calls void matrix_matrix_mult(size_t m,size_t n, int mat1[m][n], int mat2[m][n], int res[m][n]) { """Matrix vector product as sum of list comprehension doing element-wise multiplication using MKL""" double beta = 0.0; double alpha = 1.0; cblas_dgemm(CblasRowMajor, CblasNoTrans, CblasNoTrans, m, n, n, alpha, A, m, B, n, beta, C, n);}






C PROGRAMMING DATA ANALYSIS | SCALABILITY AND COMPLEXITY
As we process each graph, we notice that with either version or system, the data follows different trends. Some are increasing in nature, some monotonic, and others plateau at a certain point of operation. Specifically focusing on Version 2 of the implementation on PSC Bridges. As the number of elements increase to a certain point (1.6k), the graphs plateaus. This could be expected from the utilization of both MKL Intel and the multicore system of PSC Bridges. Looking closer at the graphs, we notice that the ECE Computing machine on version 2 of the implementation has the lowest FLOPS. This directly correlates to the linear algebra operation utilizing the least amount of resources to complete the operation. The efficiency rating can be expected given the number of available cores on ECE computing cloud.
Matrix-Matrix Product
To define multiplication between a matrix A and a vector x, we need to view the vector as a column matrix. We define the matrix-vector product only for the case when the number of columns in A equals the number of rows in x. So, if A is an m×n matrix, then the product Ax is defined for n×1 column vectors x. If we let Ax=b, then b is an m×1 column vector. In other words, the number of rows in A determines the number of rows in the product b. This can be expressed in the form:

Below is Version 1 and Version 2 of the Python and C implementations. Also listed is the resulting operations graph.
# VERSION 1 via built in operations def matrix_matrix_multiplication_version1(matrix_a,matrix_b): """Matrix-Matrix product as sum of list comprehension doing element-wise multiplication""" res = [[0 for x in range(len(matrix_a))] for y in range(len(matrix_b[0]))] for i in range(len(matrix_a)): for j in range(len(matrix_b[0])): for k in range(len(matrix_b)): res[i][j] += matrix_a[i][k] * matrix_b[k][j] return res # VERSION 2 via library calls def matrix_matrix_multiplication_version2(matrix_a,matrix_b): """Matrix-Matrix product as sum of list comprehension doing element-wise multiplication""" return np.dot(matrix_a,matrix_b)






PYTHON DATA ANALYSIS | SCALABILITY AND COMPLEXITY| SCALABILITY AND COMPLEXITY
As we process each graph, we notice that with either version or system, the data follows different trends. Some are increasing in nature, some decreasing in nature, and others monotonic. Specifically focusing on Version 1 of the implementation on ECE Computing Cluster, as the number of elements increase to a certain point (200), the graphs decreases in the number of FLOPS. Looking closer at the graphs, we notice that the AWS Elastic Compute cloud on version 1 of the implementation has the lowest FLOPS ratio. This directly correlates to the linear algebra operation utilizing the least amount of resources to complete the operation.
C PROGRAMMING LANGUAGE
# VERSION 1 via built in operations void block_matrix_matrix_mult(int block, int n, int A[n][n], int B[n][n], int C[n][n]) { """Matrix-Matrix product as sum of list comprehension doing element-wise multiplication""" int i, j, k, kk, jj; double sum; int size; size = block * (n/block); for (i = 0; i < en; i += block){ for (j = 0; j < en; j += block){ for (k = 0; k < n; k++){ for (jj = j; jj < j + block; jj++){ sum = C[k][jj]; for (ii = i; ii < i + block; ii++){ sum += A[k][ii]*B[ii][jj];} C[k][jj] = sum }}}}} # VERSION 2 via library calls void matrix_matrix_mult(size_t m,size_t n, int mat1[m][n], int mat2[m][n], int res[m][n]) { """Matrix-Matrix product as sum of list comprehension doing element-wise multiplication""" double beta = 0.0; double alpha = 1.0; cblas_dgemm(CblasRowMajor, CblasNoTrans, CblasNoTrans, m, n, n, alpha, (const double *)mat1, m, (const double *)mat2, n, beta, (double *)res, n);}






C PROGRAMMING DATA ANALYSIS | SCALABILITY AND COMPLEXITY
As we process each graph, we notice that with either version or system, the data follows different trends. Some are increasing in nature, some monotonic, and others plateau at a certain point of operation. Specifically focusing on Version 2 of the implementation on PSC Bridges. As the number of elements increase to a certain point (1.6k), the graphs plateaus. This could be expected from the utilization of both MKL Intel and the multicore system of PSC Bridges. Looking closer at the graphs, we notice that the AWS Elastic Compute cloud on version 2 of the implementation has the lowest FLOPS. This directly correlates to the linear algebra operation utilizing the least amount of resources to complete the operation.
Integer Power of Matrix
To define integer multiplication between a matrix A and a vector x, we need to view the vector as a column matrix. Given a square matrix A, for n being a nonnegative integer, An is defined as the product matrix taking A and multiplying it by itself n-times. If A is invertible, then A−n=(A−1)n, or the product matrix taking A−1 and multiplying it by itself n-times. This can be expressed in the form:

Below is Version 1 and Version 2 of the Python and C implementations. Also listed is the resulting operations graph.
# VERSION 1 via built in operations def integer_power_of_matrix_version1(matrix_a,power): """Integer power of matrix as sum of list comprehension doing element-wise multiplication""" for i in range(1,power): matrix_a = matrix_matrix_multiplication_version1(matrix_a,matrix_a) return matrix_a # VERSION 2 via library calls def integer_power_of_matrix_version2(matrix_a,power): """Integer power of matrix as sum of list comprehension doing element-wise multiplication using numpy""" return matrix_power(matrix_a, power)






PYTHON DATA ANALYSIS | SCALABILITY AND COMPLEXITY
As we process each graph, we notice that with either version or system, the data follows different trends. Some are increasing in nature, some decreasing in natrue, and others monotonic. Specifically focusing on Version 2 of the implementation on PSC Bridges. The ratio of FLOPS seems to at first decrease at the start, increase and then resultantly decreases again. Looking closer at the graphs, we notice that the AWS Elastic Compute Cloud on version 1 of the implementation has the lowest FLOPS ratio. This directly correlates to the linear algebra operation utilizing the least amount of resources to complete the operation. The efficiency rating can be expected given the number of available cores on AWS Elastic Compute Cloud.
C PROGRAMMING LANGUAGE
void integer_power_of_matrix(size_t m,size_t n, int A[n][n], int C[n][n]) { """Integer power of matrix as sum of list comprehension doing element-wise multiplication""" for (i = 1; i < power; i++){ for (i = 0; i < m; i++) { for (j = 0; j < n; j++) { C[i][j] = 0; for (k = 0; k < n; k++) C[i][j] += A[i][k]*A[k][j]; } }} void matrix_matrix_mult(size_t n, int A[n][n], int B[m][n], int C[n][n]) { """Integer power of matrix as sum of list comprehension doing element-wise multiplication""" vdPow(n,A,B,C);;}






C PROGRAMMING DATA ANALYSIS | SCALABILITY AND COMPLEXITY
As we process each graph, we notice that given either version or system, the data follows different trends. Some are increasing in nature, some decreasing in nature, and others monotonic. Specifically focusing on Version 1 of the implementation on PSC Bridges. The ratio of FLOPS seems to at first increase dramatically and then decreases, steadily. Looking closer at the graphs, we notice that the AWS Elastic Compute Cloud on version 1 of the implementation has the lowest FLOPS ratio. This directly correlates to the linear algebra operation utilizing the least amount of resources to complete the operation. The efficiency rating can be expected given the number of available cores on AWS Elastic Compute Cloud.
PERFORMANCE OPTIMIZATION and CONCLUSION
After accessing the graphical implementations, we can see that different machines yielded better results depending on the linear algebra operations. Overall, version 2 of either programming environment yielded the best results. This is because these versions maximizes all available resources of the computing machine and library calls. We can see by the summary of results
Scalar-Vector Multiplication | PSC Bridges | C Programming Version 2
Matrix-Vector Multiplication | ECE Compute Cluster | C Programming Version 2
Matrix-Matrix Multiplication | AWS Elastic Compute Cloud | Python Version 2
Integer Power of Matrix | ECE Compute Cluster | C Programming Version 2
Although given a limited amount of available resources in a constrained environment, we can conclude that the ECE computing cluster on version 2 of the implementation saves on both operation cost while meeting efficiency expectations as the size of the elements increases.
RESOURCES
Daly, Donald J., and Donald J. Daly. “Economics 2: EC2.” Amazon. CGA Canada Publications, 1987. https://aws.amazon.com/ec2/instance-types/
Nykamp , Duane Q. “Math Insight.” Multiplying matrices and vectors - Math Insight. Accessed May 14, 2020. https://mathinsight.org/matrix_vector_multiplication.
“Computer Clusters.” User Guide. Accessed May 14, 2020. https://userguide.its.cit.cmu.edu/research-computing/computer-clusters/.
“Users User Guide Account File Spaces Transferring Files Running Jobs Software.” PSC. Accessed May 14, 2020. https://www.psc.edu/bridges.
Github Repo
https://github.com/michaelm396/Matrix_Multiplcation